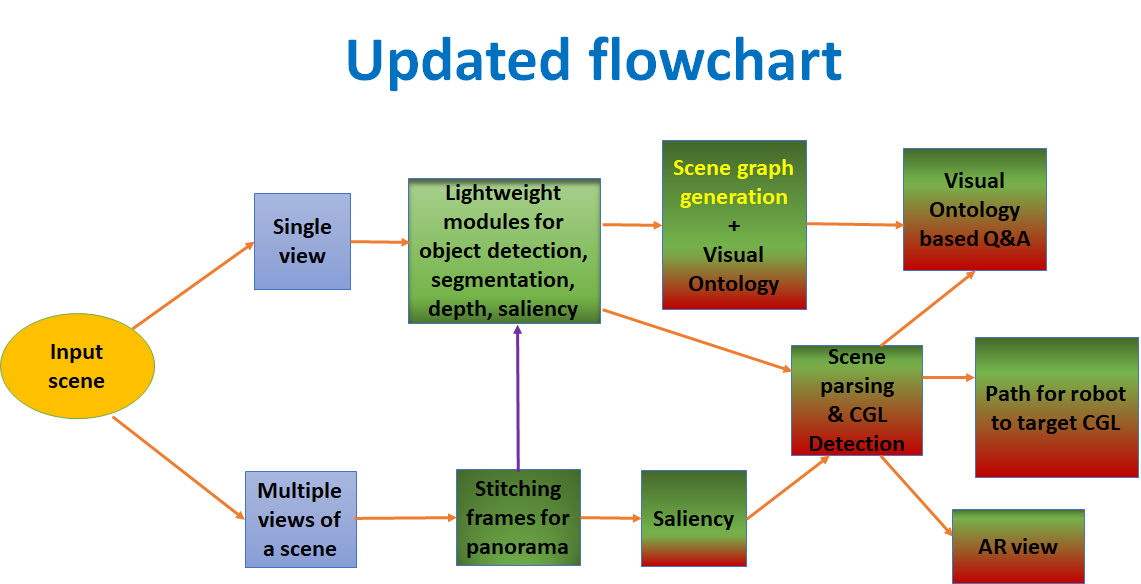
Scene Understanding for Identification of covert Geo-locations in a scene, using a Hyper-Classifier based Visual Intelligent system (2017 - 2022)
Sponsors: MHRD (GOI), CAIR (DRDO)
Last modified: September, 2022
Objectives:
The objectives involves designing software modules for:
- Scene segmentation, object saliency detection, 3-D depth maps, reconstruction and recognition of object; and Scene Ontology*.
- Latent SVM and SOM based Hyper-classifier to learn and identify spatial locations for concealment, by fusing information/cues; Scene Ontological* descriptors will be developed for this purpose.
- A faster R-CNN based Deep Learning model trained (end-to-end) directly from labeled image samples for detection of covert geolocations.
- Deployment on a mobile robot* for verification of the prototype design.
* - With collaboration and guidance of CAIR (DRDO), as per proposal
Deliverables:
- Software prototypes which analyses multiple video/image frames for identification of potential scene locations for concealment. Software will have modules for stitching, segmentation, object detection/recognition, depth map from video.
- Algorithm designed to train and test a Hyper-classifier for fusing heterogeneous (blobs, depth maps, object categories, scene ontologies) inputs as cues, for obtaining the solution to deliver predictions of geo-locations for concealment.
- Scene Ontological Extraction and Representation (with task support, guidance and aid from CAIR, DRDO) - Annotated Video and Image datasets will be developed for: (a) scene ontology creation; as well as (b) training a Hyper-classifier with ground truth labels of obscured target geo-locations for concealment. The category of object classes and usage scenarios to be identified upfront; CAIR, DRDO will partly take this work.
- Deep learning models based on Caffe and YOLO will be used to perform end-to-end training for a modified deep learning faster RCNN architecture.
- Software modules developed at IIT Madras, to be deployed on a programmable mobile robot with sensors (RGBD, LIDAR) task to be executed with support from collaborator - with CAIR (DRDO), Bangalore. This will aid visual navigation capability and detection of covert geo locations for a robot.
PI(s) :
- Prof. Sukhendu Das (Dept. of CSE)
- B. Ravindran (Co-PI) (Dept. of CSE)
- Kaushik Mitra (Co-PI) (Dept. of EE)
Project Associates :
- Binoy Shankar Saha (M.S)
- Ramya Thanga
- Sadbhavana Babar (M.S)
Project Officer :
- Kitty Varghese(M.S.)
Mtech Students :
- Jankiram Yellapu
- Ravi Kumar
- Rituparna Adha
Project Assistants :
- Ajay K
Introduction
The purpose of creating this Dataset is to aid in visual scene understanding by deriving contextual relationship between objects present in the scene. The dataset is collected for Imprint project under MHRD Initiative. It is collected in a duration 3-4 months with the help of 5 people. It contains images extracted from videos captured inside IITM Campus. The average length of a video is 30 seconds. The Dataset contains 30 different categories of objects.
Dataset



Dataset Details
The dataset consists of the following 25 classes. At present it consists of approximately 10K images.| Backpack | Clock | Mouse | Switch |
| Book | CPU | Phone | Table |
| Bottle | Cupboard | Printer | TV_Monitor |
| FireExtinguisher | Fan | Refrigerator | WaterCan |
| Person | Board | Chair | Keyboard |
| Box | Table | Dustbin | Sofa |
| Shelf | suitcase/bag | packing box | shoulder/hand bag |
| bedside table/tea table/Rack |
| Number of classes | Number of frames | Frames Annotations |
| 25 | 10K | 10K |
Introduction
This dataset is created to aid in visual scene understanding by detecting covert geo-locations or potential locations for hideout in the scene. The dataset is collected for the Imprint project under MHRD Initiative. It is collected over a span of 6 months with the help of 13 people. It contains images extracted from videos captured inside IITM Campus. The average length of a video is 45 seconds. Currently, we have 1500 frames annotated in this dataset.
Link to the CGL dataset
Sample Annotations









Dataset Details
Images
Existing computer vision datasets do not contain CGL centric real-world images, so we have curated a novel collection of images for CGL detection. Images of our dataset were captured using a Nikon D7200 DSLR camera. We intentionally avoided any humans in the view, to make the images of our dataset realistic from the point of view of the application (counter-insurgency operations) and to avoid violation of ethical norms. Our dataset consists of 1400 real-world images depicting diverse environments. To build robust models that can handle varied lighting conditions, we have captured some of the images in broad daylight and some of the images during nighttime in normal lighting conditions. As will be the case with images encountered by the model in the real-world, images in our dataset contain naturally occurring shadows and glares. Images were captured in corridors, residential houses, offices, labs, classrooms, large dining halls, seminar halls, etc. The majority of our images depict indoor scenes and a few images depict building premises. Our images are of dimension 1080 x 1920 (H x W).
Annotations
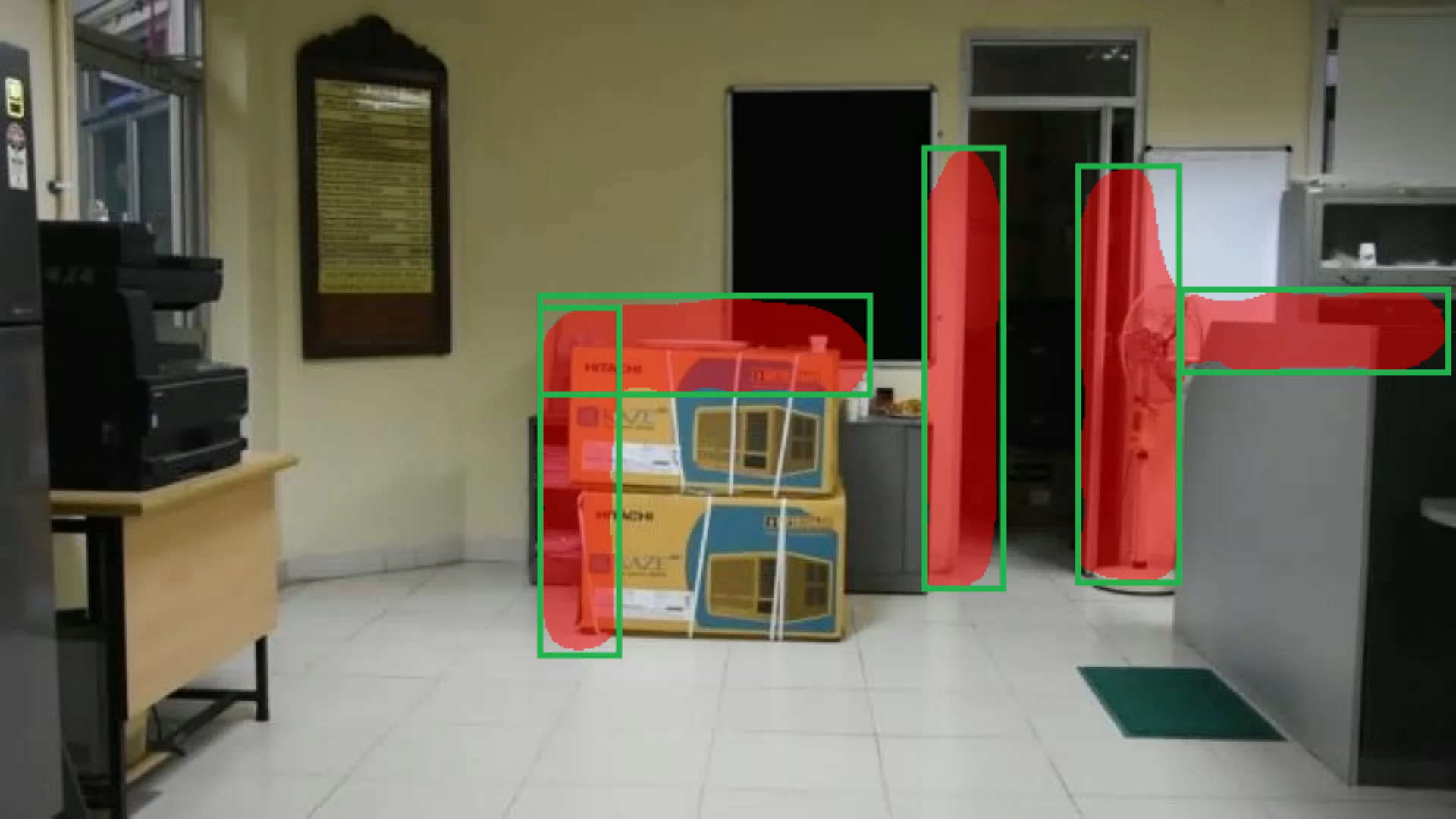
CGLs usually lie around the edges of items like furniture, pillars, doors, windows, staircase, etc. Hereafter, we refer to these items as obscuring items. We define image regions around edges of obscuring items as CGLs. Anyone (or any item) hiding behind any obscuring item will first come in the view from these regions, making these regions locations of threat as well as of interest for automated exploration of the environment. CGL bounding boxes have been annotated such that approximately 50% of the area inside the bounding box contains the obscuring item and 50% lies outside. CGLs in our dataset are of two types: horizontal (wherein the height of the bounding box enclosing the CGL is less as compared to its width) and vertical (wherein the width of the bounding box is less as compared to its height). For the height of vertical CGLs, the average human’s height (as perceived in the scene) was used as a measure to annotate. Our dataset contains ~13K CGLs, out of which ~60% are vertical CGLs and ~40% are horizontal CGLs. Annotations are stored in MS COCO JSON format.
Introduction
In this project we are finding out the salient object which could be treated as a possible threat. Saliency is what stands out to you and how you are able to quickly focus on the most relevant parts of what you see. In neuroscience, saliency is described as an attention mechanism in organisms to narrow down to the important parts of what they see.
Dataset


Dataset Details
| Number of frames | Frames Annotations |
| 100 | 100 |
Please use latest Chrome version for best viewing.
Page contains Demos of finding Covert Geo-Locations(CGL), Active and Passive Navigation, Floor Plan estimation and Saliency in panorama.
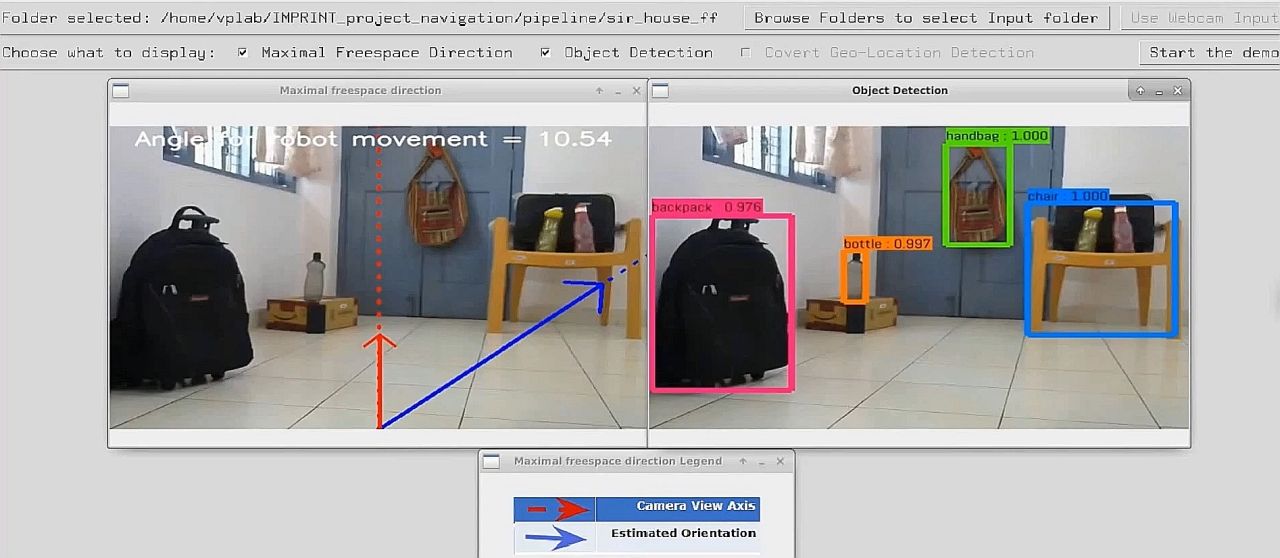
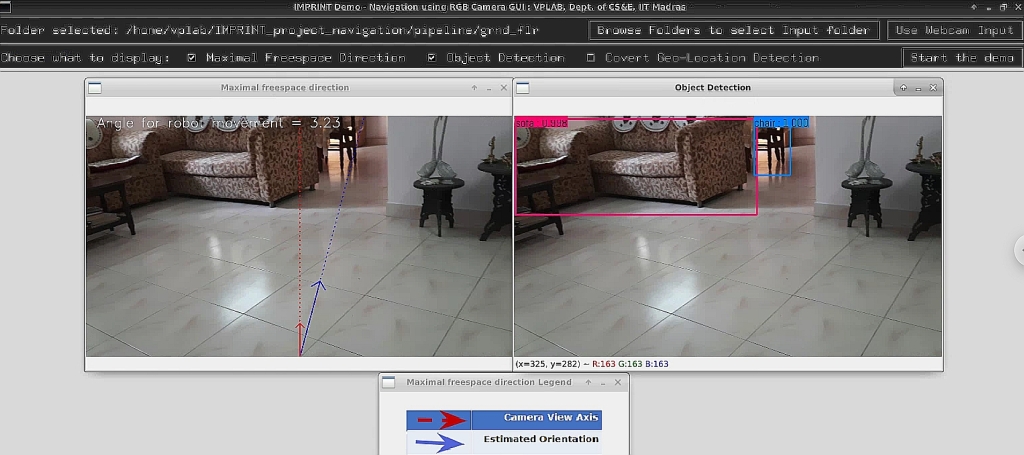





- IMPRINT Github Page(here)
- Covert Geo-location Dataset (CGL Dataset)
- Object Dataset (VPOD) - coming soon!
- Saliency in panorama Dataset - coming soon!